Implementing the Model
important
Before following the tutorial, you should have:
- PyTorch installed in your machine. Read instructions here.
- CSV file with dataset from Preparing Dataset for PyTorch.
Matrix Factorization Model in PyTorch
Taking the idea of Matrix Factorization, let's implement this in PyTorch.
First, let's import some necessary modules.
Next, let's build our Matrix Factorization Model class.
To instantiate our model, we can simply call on it like so:
note
The variables num_users and num_items represent the number of unique users and unique items in the dataset respectively.
Currently, this is what the dataset looks like:
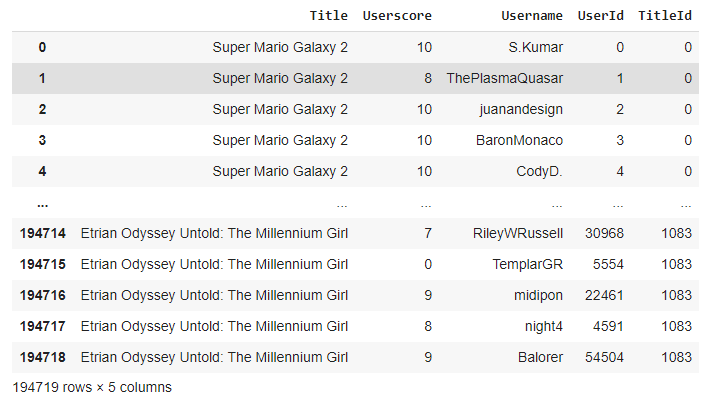
The items here are games that we want to recommend to users.
Once the model is instantiated, we can proceed to split our dataset to train and test our model. The general split is 20% test and 80% training.
Now, we want to create our training function to train the model.
In each iteration, the training function is updating our model to approach a smaller MSE (mean squared error). This is the idea of gradient descent.
And finally, we want to create our test function, which will be called right after training is done.
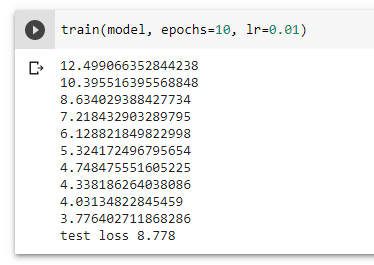
We can see that although our model's lowest MSE in our training dataset was about 3.776, the actual MSE based on our test dataset is about 8.778. Generally, this is a normal result, but a big difference between the training and test MSE likely suggests that our model is overfitted.
Model Prediction
And now, we are ready to use our model for prediction! For example, to predict the ratings of games for user of user id 10, we can run the following lines:
Notice that some of the predictions went over 10. To fix this, we can simply normalize our results like so:
Finally, we can recommend some games by sorting our predictions list: