Menerapkan Model
important
Sebelum mengikuti tutorial, Anda harus memiliki:
- PyTorch dipasang di mesin Anda. Baca petunjuknya di sini.
- File CSV dengan set data dari Mempersiapkan Set Data untuk PyTorch.
Model Faktorisasi Matriks di PyTorch
Mengambil ide dari Faktorisasi Matriks, mari kita terapkan ini di PyTorch.
Pertama, mari impor beberapa modul yang diperlukan.
Selanjutnya, mari kita buat kelas Model Faktorisasi Matriks.
Untuk membuat contoh model kita, kita cukup memanggilnya seperti ini:
note
Variabel num_users dan num_items masing-masing mewakili jumlah pengguna unik dan item unik dalam kumpulan data.
Saat ini, seperti inilah kumpulan data tersebut:
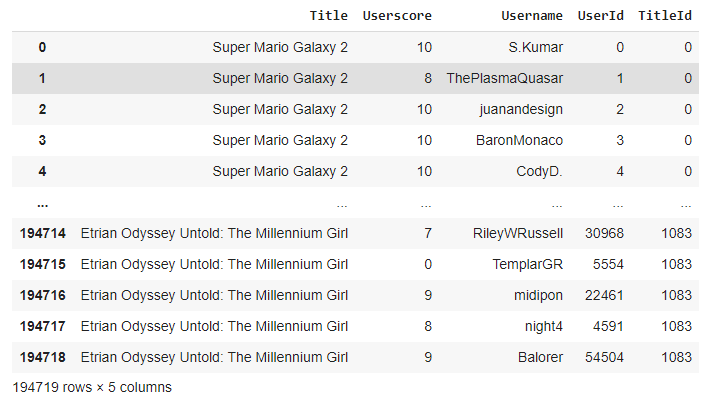
Item di sini adalah game yang ingin kami rekomendasikan kepada pengguna.
Setelah model dibuat, kita dapat melanjutkan untuk membagi kumpulan data untuk melatih dan menguji model kita. Pembagian umum adalah tes 20% dan pelatihan 80%.
Sekarang, kami ingin membuat fungsi pelatihan untuk melatih model.
Di setiap iterasi, fungsi pelatihan memperbarui model kita untuk mendekati MSE yang lebih kecil (mean squared error). Ini adalah gagasan penurunan gradien.
Dan terakhir, kami ingin membuat fungsi pengujian kami, yang akan dipanggil tepat setelah pelatihan selesai.
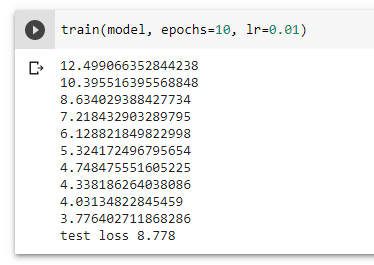
Kami dapat melihat bahwa meskipun MSE terendah model kami dalam kumpulan data pelatihan kami adalah sekitar 3.776, MSE aktual berdasarkan kumpulan data pengujian kami adalah sekitar 8.778. Secara umum, ini adalah hasil yang normal, tetapi perbedaan besar antara MSE pelatihan dan pengujian kemungkinan menunjukkan bahwa model kami terlalu pas.
Prediksi Model
Dan sekarang, kami siap menggunakan model kami untuk prediksi! Misalnya, untuk memprediksi rating game untuk pengguna user id 10, kita dapat menjalankan baris berikut:
Perhatikan bahwa beberapa prediksi melebihi 10. Untuk mengatasinya, kita cukup menormalkan hasil kita seperti ini:
Terakhir, kami dapat merekomendasikan beberapa game dengan mengurutkan daftar prediksi kami: